行銷人轉職爬蟲王實戰|5大社群+2大電商
1. Html網頁結構介紹-網頁到底如何傳送資料?爬蟲必學
2. 資料傳遞:Get與Post差異,網路封包傳送的差異
3. Html爬蟲Get教學-抓下Yahoo股票資訊,程式交易的第一步
4. Html爬蟲Get實戰-全台最大美食平台FoodPanda爬蟲,把熊貓抓回家
5. 資料分析實戰,熊貓FoodPanda熱門美食系列|看出地區最火料理種類
6. Json爬蟲教學-Google趨勢搜尋|掌握最火關鍵字
7. Json爬蟲實戰-24小時電商PChome爬蟲|雖然我不是個數學家但這聽起來很不錯吧
8. Html爬蟲Post教學-台灣股市資訊|網韭菜們的救星
9. Html爬蟲Post實戰-全球美食平台UberEat爬蟲
10. Pandas爬蟲教學-Yahoo股市爬蟲|不想再盯盤
11. Pandas爬蟲實戰-爬下全台各地區氣象預報歷史資料
12. 資料分析實戰-天氣預報圖像化|一張圖巧妙躲過雨季
è¦ç®å¸å ´å¤§å°é ä¼°åæï¼K-meanså群ç實ä¾æç¨
1. 課ç¨ä»ç´¹
éæ²çãç¢åéç¼å¤§è£å¸ï¼æ¡è³¼ç好幫æï¼å¦ä½æ±ºå®æ°ååSKUï¼ãï¼éä¸å¿«æåé»æï¼ å¨åç¯æç« ããè¦ç®ç¬è²ãæ詳細ææææå¸ï¼ååè³æï¼çè¨è©è«ãç¶ä¸å·²ç¶åå¾äºå¨è¦ç®å¸å ´ä¸ï¼ææãè±è¥¯è¡«ãç¢åçååè³æï¼éåå¸å ´æ幾種æ¶è²»é¡ç¾¤å¢ï¼æ¯åé¡ç¾¤çå¸å ´ç¸½é¡æ¯å¤å°å¢ï¼åªè£¡ææå¸å ´ç¼ºå£å¢ï¼
ä½ æç¼ç¾åï¼è¦ç®çæ¯åååçºäºå¢å 被æå°å°çæ©çï¼æç¡éå°å°åååçç¹è²å¯«å¨ãæ¨é¡ãæè ãå §æ Tagãç¶ä¸ï¼çæ¼æ¯è³£å®¶å¹«æåãæåååé¡ãäºï¼èå çºæ¶è²»è ä¿è·æ³çéä¿ï¼è³£å®¶ä¹ä¸è½äºå¯«ååç¹è²ãå æ¤æåé²è¡å¸å ´å群çåçï¼ä¾¿æ¯ä¾ç §è³£å®¶å°æ¯åååç Tagé²è¡åé¡ã
2. å¯äº¤ä»ææ
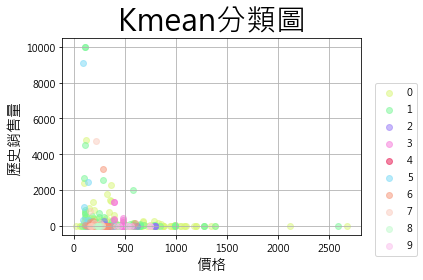 æåå©ç¨ææ競çå» åçé·å®è³æï¼ä¾ç
§ç«¶çå» å給ååç Tagï¼å©ç¨K-means æ¼ç®æ³å°æ¯ååååé¡ãç±çµæï¼ä¸åï¼å¯ä»¥çå°ï¼æ¯åé»ä»£è¡¨ä¸ç¨®ååï¼èä¸åè·è²ä»£è¡¨ä¸åçé¡ç¾¤ã
æåå©ç¨ææ競çå» åçé·å®è³æï¼ä¾ç
§ç«¶çå» å給ååç Tagï¼å©ç¨K-means æ¼ç®æ³å°æ¯ååååé¡ãç±çµæï¼ä¸åï¼å¯ä»¥çå°ï¼æ¯åé»ä»£è¡¨ä¸ç¨®ååï¼èä¸åè·è²ä»£è¡¨ä¸åçé¡ç¾¤ã
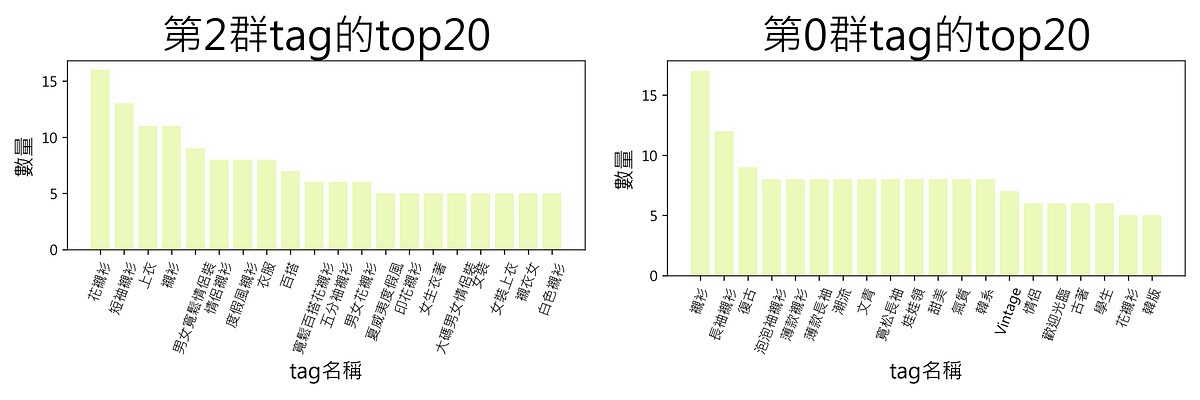
åé¡å®æå¾å¯ä»¥å¨ç¢åºæ¯åé¡ç¾¤çé«é »ç Tagï¼å æ¤è¥åé¡æ10群ï¼å°±ææ10å¼µ Tagé »çåãï¼å¦ä¸åï¼ï¼å¨ç¶éä¸çªå¯©è¦ï¼ä¸é£ç¼ç¾ç¬¬0群èéå¨ã復å¤é風ãï¼èº«åæéç³»ååæãç¸åç第2群é½æ¯ãæµ·çè±è¥¯è¡«ãï¼å
©è
ç客群å¯æ³èç¥ï¼
3. æ´çååTag
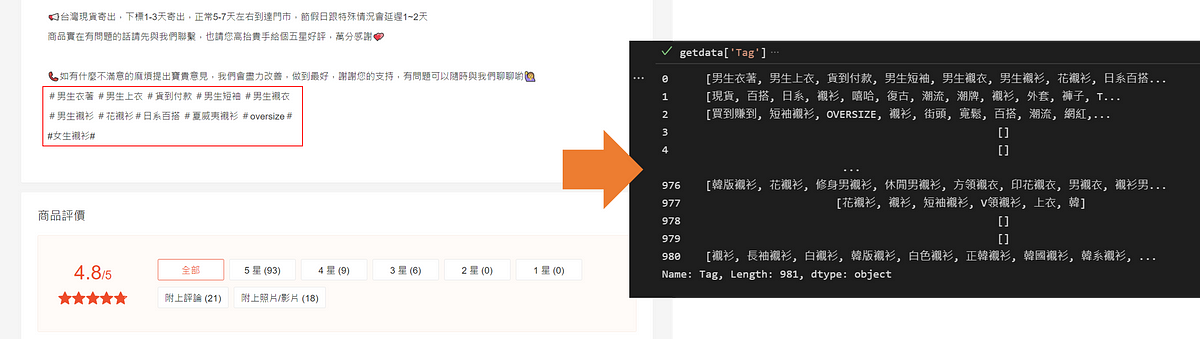 å¨K-meanså群åï¼å¿
é è¦å
å°æ¯åååç Tagè³ææ´çåºä¾ãé裡æ¯è¼ç¹å¥çæ¯ï¼è¥ Tagçåæ¸å¤§æ¼10ååæåä¸è¨å
¥ï¼å
¶åå å¨æ¼ï¼è¨±å¤æåå家æå©ç¨ Tagä¾æä¸äºèªå·±çåè¨ãç¬è©±ãå
§å¿OSççï¼éäºæ ¹ååæ¬èº«ä¸¦ç¡éä¿ï¼å æ¤äºä»¥æé¤ã
å¨K-meanså群åï¼å¿
é è¦å
å°æ¯åååç Tagè³ææ´çåºä¾ãé裡æ¯è¼ç¹å¥çæ¯ï¼è¥ Tagçåæ¸å¤§æ¼10ååæåä¸è¨å
¥ï¼å
¶åå å¨æ¼ï¼è¨±å¤æåå家æå©ç¨ Tagä¾æä¸äºèªå·±çåè¨ãç¬è©±ãå
§å¿OSççï¼éäºæ ¹ååæ¬èº«ä¸¦ç¡éä¿ï¼å æ¤äºä»¥æé¤ã
from tqdm import tqdm
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import pandas as pd
colors = ['#d9f776','#76f794','#9476f7','#f776d9','#e70e4b','#76d9f7','#f79476','#fbccbe','#befbcc','#fbbeed']
getdata = pd.read_csv('è±è¥¯è¡«_ååè³æ.csv', encoding='utf-8')
getdata.columns
#--- è¥æ²ætagï¼åå¾æç« ä¸æ´çåºTag
containar = []
for i in range(len(getdata)):
getArticle = getdata['ååææ¡'][i] #æåæ¯ç¯ææ¡
getArticle = getArticle.replace('ï¼','#') # åå½¢å
¨å½¢ä¸è´
item = []
for j in getArticle.split('#'): # å©ç¨ã#ãä¾ååå²
if len(j) < 10 : # è¥tag大æ¼10åååä¸è¨å
¥
j = j.replace(' ','') # å代空ç½
j = j.replace('^n','') # å代^n
if len(j) >0 : # è¦ç¢ºèªå代å®æå¾éæå©ä¸æ±è¥¿
item.append(j)
containar.append(item)
getdata['Tag'] = containar
4. è³ææ´ç
é¦å å å°ååIDãå¹æ ¼ãæ·å²é·å®éãTagéååæ¬ä½æååºä¾ï¼å ¶å¯¦é¤äº Tag以å¤ï¼å©ä¸çæ¬ä½ä¸»è¦æ¯åè¦è¦ºåææ使ç¨ï¼å æ¤åªæ¯è¦ç¢åºå ±ååå®ï¼åå¯ä»¥çç¥å¹æ ¼ãæ·å²é·å®éæ¬ä½ã
#--- æ´çæå¯ä»¥è¢«Kmeanåæçè³æ
KmeansData = getdata[['ååID','å¹æ ¼','æ·å²é·å®é','Tag']]
è¦å¦ä½è¨ç®ä½¿ç¨çæé«çTagå¢ï¼ éååé¡ä¹å°æ¾äºæå¾ä¹ ï¼å ¶å¯¦éä½çåçç°¡å®ãé¦å å©ç¨pandas æ¬èº«å §å»ºçsum() æ¹æ³ï¼æææååçTag å ¨é¨ä¸²æ¥æä¸åListè®æ¸ï¼ä¸¦å©ç¨pd.DataFrame() æ¹æ³å°Listè½æædataFrame åæ è³æã
allpro = KmeansData['Tag'].sum()
allpro = pd.DataFrame(allpro)
allpro.dropna(inplace=True)
å°Listè½æædataFrame åæ è³æçç®çå¨é裡就顯ç¾åºä¾äºãæåå¯ä»¥å©ç¨value_counts() æ¹æ³ä¾é濾æéè¤çTag ï¼ä¸¦ä¸éæ幫æåå¾åºç¾æ¬¡æ¸æå¤çTag éå§é²è¡æåºãæ¥èå©ç¨np.where() ècontains() æ¹æ³ï¼ä¾è¨ç®æ¯åååæ¯å¦æåºç¾è©²Tag ï¼å¦æ¤ä¸ä¾ä¾¿å¤§ååæäºã
KmeansData['Tag'] = KmeansData['Tag'].astype(str)
count=0
for i in tqdm(allpro[0].value_counts().index):
KmeansData['c'+str(count)] = np.where(KmeansData['Tag'].str.contains(i),1,0)
count = count+1
ä¸åæ¯è¨ç®å®æççµæãc0ï½c1228 代表çæ¯æ1228åTagï¼å
¶å¯¦æ´å¤ï¼ï¼ä¸æ¹çè³æ0代表æ²æå¨ååææ¡ä¸åºç¾è©²Tagï¼åä¹è³æ1代表æåºç¾ãæ¨å¯è½æå¾å¥½å¥çºä½è¦ä½¿ç¨c0ï½c1228 é²è¡å½åï¼çºä½ä¸ç´æ¥å°Tag çå
§å®¹ç¶ä½æ¨é¡Indexï¼å
¶åå å¨æ¼æ¹ä¾¿ä¹å¾çè¿´åè¨ç®ï¼ä¸¦ä¸çççKmeans æ¼ç®æ³ä¸ï¼ä¹ä¸è½æä¸æåºç¾ï¼å æ¤ç´æ¥ç¨çµ±ä¸ç編碼ç¸å°çæ¹ä¾¿è¨±å¤ã

5. K-meanså群å¸å ´
å°ä¸åæ¥é©çæ¬ä½å ¨é¨é¤µå ¥Kmeansæ¼ç®æ³é²è¡åé¡ã
#--- éå§åé¡
crub = 10 #總å
±è¦åæ幾群
clf = KMeans(n_clusters=crub)
clf.fit(KmeansData[['c'+str(x) for x in range(count)]].values.tolist())#éå§è¨ç·´
#--- åå¾é 測çµæ
getdata['é¡ç¾¤'] = clf.labels_
6. Kmeanåé¡å
çµæï¼ä¸åï¼å¯ä»¥çå°ï¼æ¯åé»ä»£è¡¨ä¸ç¨®ååï¼èä¸åè·è²ä»£è¡¨ä¸åçé¡ç¾¤ãç±æ¼ç¹ªåçXY軸æ¯å¹æ ¼èæ·å²é·éï¼èKmeansçåé¡ä¾ææ¯ä¾ç
§Tagï¼å æ¤ææ覺æ¤åä¸ä¸¦æ²æç麼è¦å¾ï¼é£æåå¯ä»¥æ¥èä¸ä¾çæ¯åé¡ç¾¤ä¸æ¯ä¸æ¯ççæä¸äºç¹è²ï¼Kmeansæ¼ç®æ³æå°ä»åæ¸çºä¸é¡ã
#--- Kmeanåé¡å
for i in range(crub):
draw = getdata[getdata['é¡ç¾¤']==i]
print('第' + str(i) + '群æ¸éï¼ã' + str(len(draw)))
plt.scatter(draw['å¹æ ¼'],draw['æ·å²é·å®é'],
color=colors[i],
label = i,
alpha=0.5)
plt.title("Kmeanåé¡å",fontsize=30)#æ¨é¡
plt.xlabel("å¹æ ¼",fontsize=15)#yçæ¨é¡
plt.ylabel("æ·å²é·å®é",fontsize=15) #xçæ¨é¡
plt.legend(bbox_to_anchor=(1.03, 0.8), loc=2) # è¨ç½®åä¾
plt.grid(True) # grid éå
plt.tight_layout()
7. å群ééµåTop 20
ç¹å¥çååºæ¯å群é«å¾å°±å¯ä»¥ç¼ç¾ï¼ç¬¬0群èéå¨ã復å¤é風ãï¼èº«åæéç³»ååæãç¸åç第2群é½æ¯ãæµ·çè±è¥¯è¡«ãï¼å æ¤éå
©å群é«æå¾é¡¯èç客群ã
æä¸æåºç¾æ²æç¹è²ç群é«å¢ï¼çµå°æï¼ åå å¨æ¼å¸å ´å¤§å¤æ¸ç¢åéæ¯æ²æååéåçï¼å管å¸å ´åéçè«å·²ç¶åºä¾äºååä¸ç´ï¼ä½çµå¤§å¤æ¸çæ¥ä¸»ï¼é½éæ¯å¸æä»åçååè½å å±±å æµ·çè¿åå層ç´æ¶è²»è ã
éååé¡çèçæ¹å¼ï¼æ¯å°é£äºæ²æç¹è²ç群é«ï¼å ¨é¨æ¸é¡å°ãç¡åã群é«ä¹ä¸ï¼ç±æ¼æ²æç¹è²ï¼å æ¤ä¹æ²æç¹å¥åæçå¿ è¦æ§äºãä¾ç §ä½è ä¹åçç¶é©ï¼å¨è¦ç®ä¸é樣çãç¡åã群é«æ¯ä¾å¤§ç´æä½å¸å ´ç50ï½70% ä¹éï¼å ¶å¯¦ä¹æ¯ä¸å°çæ¸ç®ãä½è æ¨æ·æ該æ¯è¦ç®å¸å ´æ¬èº«ååååå®å¹é½åä½ï¼å æ¤é路客è¼å¤ï¼å¤æ¸ååºä¹ä¸å®¹æå¹è²å¿ 實顧客ã
#--- å群tag top 20
for i in range(10)
draw = getdata[getdata['é¡ç¾¤']==i]
draw = pd.DataFrame(draw['Tag'].sum())[0].value_counts()
plt.bar(draw.index[0:20],
draw[0:20].values,
color='#d9f776',
alpha=0.5)
plt.xticks(rotation=70)
plt.title("第"+str(i)+"群tagçtop20",fontsize=30)#æ¨é¡
plt.xlabel("tagå稱",fontsize=15)#yçæ¨é¡
plt.ylabel("æ¸é",fontsize=15) #xçæ¨é¡
plt.tight_layout()
plt.savefig("第"+str(i)+"群tagçtop20.png", dpi=300) # åæªä¸è¨å®è§£æ度
plt.close()
8. è¨ç®å¸å ´ç¸½å¸å¼
æå¾ä¹æ¯æ好ç©çå°æ¹ï¼åä¾å¸å ´ç¸½å¸å¼ç®èµ·ä¾é£éº¼ç°¡å®ï¼ç´æ¥å©ç¨Pandas å¥ä»¶æåºåå群é«ï¼å°è©²ç¾¤é«ææååçå¹æ ¼ä¹ä¸é·å®éï¼å³å¯ç²å¾è©²å¸å ´ç總å¸å¼äºï¼æ¨æä½æå¸å ´çå¤§é¤ åï¼
#--- å群ç總å¸å¼
getdata['總æ¶å
¥'] = getdata['å¹æ ¼'] * getdata['æ·å²é·å®é']
for i in range(10)
draw = getdata[getdata['é¡ç¾¤']==i]
print('第'+str(i)+'群總æ¶å
¥ï¼ '+str(draw['總æ¶å
¥'].sum()))
1. 總çµ
ä¹çä¹ä¸ï¼ç®åååç·ä¸è³¼ç©å¹³å°åªå©è¦ç®æä¾åååçé·éï¼å æ¤éå¥æ¹æ³ç®åä¹å é©ç¨æ¼è¦ç®ãé»åçå¸å ´ç¬æ¯è¬è®ï¼è¨±å¤æ°èçå¹³å°èè¦ççæ³è¦å¥ªä¸éå¡å¤§é¤ ï¼èå¯ç¨æèçæ¹å¼æ¯ç¡æ³æ 奪çï¼çè å°éå¥åæçæç¶çµ¦æ¨å¸¶èèµ°ï¼å¸æè½å¹«å©è®å°æå¾çæ¨ã
作者:楊超霆 行銷搬進大程式 創辦人