行銷人轉職爬蟲王實戰|5大社群+2大電商
1. Html網頁結構介紹-網頁到底如何傳送資料?爬蟲必學
2. 資料傳遞:Get與Post差異,網路封包傳送的差異
3. Html爬蟲Get教學-抓下Yahoo股票資訊,程式交易的第一步
4. Html爬蟲Get實戰-全台最大美食平台FoodPanda爬蟲,把熊貓抓回家
5. 資料分析實戰,熊貓FoodPanda熱門美食系列|看出地區最火料理種類
6. Json爬蟲教學-Google趨勢搜尋|掌握最火關鍵字
7. Json爬蟲實戰-24小時電商PChome爬蟲|雖然我不是個數學家但這聽起來很不錯吧
8. Html爬蟲Post教學-台灣股市資訊|網韭菜們的救星
9. Html爬蟲Post實戰-全球美食平台UberEat爬蟲
10. Pandas爬蟲教學-Yahoo股市爬蟲|不想再盯盤
11. Pandas爬蟲實戰-爬下全台各地區氣象預報歷史資料
12. 資料分析實戰-天氣預報圖像化|一張圖巧妙躲過雨季
Amazonç¬è²ï¼çè¨è³æï½éç¶æä¸æ¯åæ¸å¸å®¶ï¼ä½å ¨é¨ç¬ä¸ä¾å¾æ£å§ï¼ãéPythonç¨å¼ç¢¼ã
1. å¯äº¤ä»ææ
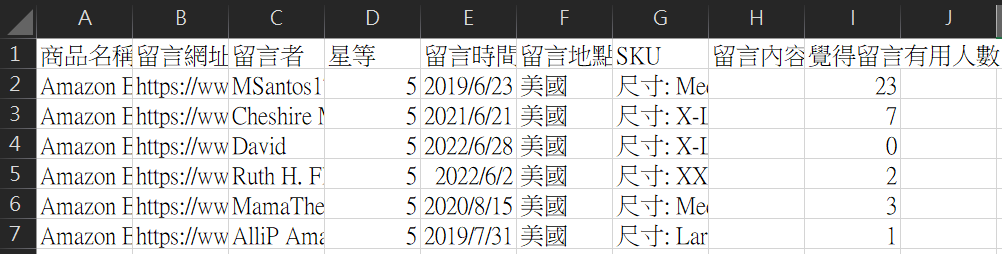 æ¥çºåé¢èª²ç¨ãAmazonç¬è²ï¼ååè³æï½ç¨Pythonç¬ä¸ä¸çæ大é»å網ç«ãéç¨å¼ç¢¼ããæç¬ä¸ä¾çååçµæï¼é²å°æ¯åååä¸ç¬ä¸ææççè¨å
§å®¹ï¼å
¶å
§å®¹å
å«ååå稱ãçè¨ç¶²åãçè¨è
ãæçãçè¨æéãçè¨å°é»(åå)ãSKUãçè¨å
§å®¹ã覺å¾çè¨æç¨ç人æ¸ã
æ¥çºåé¢èª²ç¨ãAmazonç¬è²ï¼ååè³æï½ç¨Pythonç¬ä¸ä¸çæ大é»å網ç«ãéç¨å¼ç¢¼ããæç¬ä¸ä¾çååçµæï¼é²å°æ¯åååä¸ç¬ä¸ææççè¨å
§å®¹ï¼å
¶å
§å®¹å
å«ååå稱ãçè¨ç¶²åãçè¨è
ãæçãçè¨æéãçè¨å°é»(åå)ãSKUãçè¨å
§å®¹ã覺å¾çè¨æç¨ç人æ¸ã
2. ç¬è²åæºå
å¨éå§æ¬èª²ç¨çç¬è²ä¹åï¼å¿ é è¦å å°åä¸å 課ãAmazonç¬è²ï¼ååè³æï½ç¨Pythonç¬ä¸ä¸çæ大é»å網ç«ãéç¨å¼ç¢¼ããççµææ¾å¨ç¨å¼çå·¥ä½ç®éå §ï¼è¥ä¸ç¥éå¦ä½å¨Spyder ä¸è¨å®å·¥ä½ç®éï¼ä¹å¯ä»¥åè課ç¨ãSpyder使ç¨æå¸ãã
productData = pd.read_csv('Amazonååè³æ.csv', encoding = 'utf-8')
éç¶é次çç¬è²åªéè¦ç¨get è«æ±å³å¯ï¼ä½å çºAmazon å¨å°å ä¸éæ¯æäºæª¢æ¥çï¼å æ¤request çæåéæ¯éè¦ä»ä¸header ï¼èç¶éä½è 測試ï¼å°å å §åªéè¦accept-encodingãaccept-languageãcookieãuser-agent å³å¯ï¼ä½å¨ç¬è²åéè¦ææèªå·±çåï¼
# è«æ±ä½¿ç¨Headerï¼å¯è½éè¦æ¿æcookie
head = {
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9,zh-TW;q=0.8,zh;q=0.7',
'cookie': 'session-id=136-0340723-9192226; session-id-time=2082787201l; i18n-prefs=USD; lc-main=zh_TW; ubid-main=134-3980769-3693765; sp-cdn="L5Z9:TW"; csm-hit=tb:TZMAJPK9WYNJ0Y80TMZK+s-TZMAJPK9WYNJ0Y80TMZK|1660289724778&t:1660289724778&adb:adblk_no; session-token=k3RS++Iksjl7C0tJ6mcNq0RKrVUijnLF3sGiIoxeKYwsG3aTueKJ6BGxf1Z6C+j3R4W9UBC/Jlyv24bO/e4JyDPhLhiKZs64nYY0UmUBqtBsgRAkgHnkzJ4KCI2Soocp46TvfNQe7YzoO/vHjHXoCJ0bVCvhkshLYNLWvkQTSxIJaMYOP3a0Q5rSPnicXs3+54f73HotO2JZaPwBsmnxSVPrGpZpqRNI',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
æå¾å¨æºåååList ï¼ä»¥ä¾¿æ¼ççç¬è²ççµæé²è¡å²åã
theproduct = []
theCommenturl = []
who = []
star = []
thetime = []
location = []
sku = []
comment = []
helpful = []
3. é²å°æ¯åååç¬è²
éå§é²å°æ¯ä¸åAmazon ååççè¨ä¸é²è¡ç¬è²äºï¼èå¨çè¨ä¸æ使ç¨while è¿´åä¾ç¬åçè¨ï¼å çºæåç¡æ³ç¢ºå®ç¸½å ±æå¤å°çè¨ï¼å æ¤éè¦å¨æ¯æ¬¡è«æ±å¾ï¼æª¢æ¥æç¡å¢å æ°ççè¨ï¼æç話就代表éæ²æç¬å®ã
for data in range(0, len(productData)):
# 決å®è¦æåç網å
geturl = productData.iloc[data]['çè¨ç¶²å']
doit = True # 決å®æ¯å¦ç¹¼çºé²è¡çè¨ç¬è²
page = 0 # ç¬å°ç¬¬å¹¾é
while doit:
if page == 0: # å¤æ·æ¯å¦çºç¬¬ä¸é
url = geturl
else:
url = geturl.split('/ref')[0] + '/ref=cm_cr_getr_d_paging_btm_next_'+ str(page) +'?ie=UTF8&reviewerType=all_reviews&pageNumber=' + str(page)
#è«æ±ç¶²ç«
list_req = requests.get(url, headers= head)
#å°æ´å網ç«çç¨å¼ç¢¼ç¬ä¸ä¾
soup = BeautifulSoup(list_req.content, "html.parser")
getdata = soup.find_all('div', {'data-hook':'review'})
if len(getdata) > 0: # å¤æ·æ¯å¦ææµè¨è³æï¼æ²æå°±ç´æ¥å°doitæ¹æFalseï¼åæ¢å·è¡
for i in getdata:
theproduct.append(productData.iloc[data]['ååå稱']) # å²åååå稱
theCommenturl.append(productData.iloc[data]['çè¨ç¶²å']) # å²åçè¨ç¶²å
who.append(i.find('span', {'class':'a-profile-name'}).text) # å²åçè¨è
1. ç¬åææ
ææçæååªéè¦éå°æ¨ç±¤çclass çºa-icon-alt çå³å¯ãä½ç±æ¼ä¸åèªç³»çåå ï¼æå¯è½æäºä½¿ç¨è æ¯ä½¿ç¨å°è±æçé é¢ï¼å æ¤ä¸è±æ網é çè´ åé½æ使ç¨replace() æ¹æ³å代æã
# èçææ
getstart = i.find('span', {'class':'a-icon-alt'}).text
getstart = getstart.replace(' é¡æï¼æé« 5 é¡æ','') # ä¸æ網é
getstart = getstart.replace(' out of 5 stars','') # è±æ網é
star.append(float(getstart))
2. ç¬å購買æéãå°é»
é裡主è¦èª¿æ´çé¨åæ¯è³¼è²·æéï¼è¥çºè±æ網é ï¼åç¾çæ份æ¯è±æçå ¨åï¼éæå°è´æåç¡æ³è½ædatetime æéæ ¼å¼ï¼å æ¤è¦å å°ææçæ份è±æè½ææå°æçæ¸åå¾ï¼åé²è¡è½æã
# èç購買æéãå°é»
gettime = i.find('span', {'data-hook':'review-date'}).text
if 'Reviewed' in gettime: # å¤æ·æ¯å¦çºè±æ網é
# å°è±ææ份æææ¸åï¼é樣å¾
ææè½çµ¦datetime辨å¥
gettime = gettime.replace('January','1')
gettime = gettime.replace('February','2')
gettime = gettime.replace('March','3')
gettime = gettime.replace('April','4')
gettime = gettime.replace('May','5')
gettime = gettime.replace('June','6')
gettime = gettime.replace('July','7')
gettime = gettime.replace('August','8')
gettime = gettime.replace('September','9')
gettime = gettime.replace('October','10')
gettime = gettime.replace('November','11')
gettime = gettime.replace('December','12')
gettime_list = gettime.split(' on ')
thetime.append(datetime.strptime(gettime_list[1], "%m %d, %Y")) # å²åçè¨æé
location.append(gettime_list[0].replace('Reviewed in the ','')) # å²åçè¨å°é»
else:
gettime_list = gettime.split('å¨')
cuttime = gettime_list[0].replace(' ','')
thetime.append(datetime.strptime(cuttime, "%Yå¹´%mæ%dæ¥")) # å²åçè¨æé
location.append(gettime_list[1].replace('è©è«','')) # å²åçè¨å°é»
3. ç¬å覺å¾çè¨æç¨äººæ¸
éååè½å¾åæåå¨ä¸è¬è³¼ç©ç¶²ç«æçå°çæè®åè½ï¼ä»£è¡¨æ¯æéåç¼è¨è çç«å ´ãé裡ä¹éè¦å°å¤é¤çå串å代æï¼ä¹å çºæå¿å¯è½æ¨æç¬å°åæç網é ï¼å æ¤ä¸è±æçå串å代é½å¯«é²å»äºã
# èç覺å¾çè¨æç¨äººæ¸
gethelpful = i.findAll('span', {'data-hook':'helpful-vote-statement'}) # å²å覺å¾çè¨æç¨äººæ¸
if len(gethelpful) != 0: # å¤æ·æ¯å¦æè³æ
gethelpful = gethelpful[0].text
gethelpful = gethelpful.replace(',','') # æååä½çã,ãæ¿æ
gethelpful = gethelpful.replace(' å人覺å¾æç¨','') # ä¸æ網é
gethelpful = gethelpful.replace(' people found this helpful','') # è±æ網é
if 'ä¸äººè¦ºå¾æç¨' == gethelpful or 'One person found this helpful' == gethelpful: # å¤æ·æ¯å¦åªæä¸äºº
helpful.append(1)
else:
helpful.append(int(gethelpful))
else:
helpful.append(0)
4. ç¬è購買é¡è²ã尺寸
å¨çè¨ä¸å¦ä¸åå¹å¼å°±æ¯æ¯å購買è æ購買ç樣å¼ï¼ç±æ¤è½çªºæ¢éåå¸å ´çé·éï¼é²èæ¨ç®åºé©åé²å ¥å¸å ´çä½ç½®ï¼éä¹å¯ä»¥åè課ç¨ãç¢åéç¼å¤§è£å¸ï½æ¡è³¼ç好幫æï¼å¦ä½æ±ºå®æ°ååSKUï¼ãçé輯æ¹å¼ã
# èç購買é¡è²ã尺寸
getsku = i.find_all('a', {'data-hook':'format-strip'})
if len(getsku) == 1: # å¤æ·æ¯å¦æè³æ
sku.append(getsku[0].text)
else:
sku.append(None)
5. åæª
å çºæäºååå¯è½æ²æçè¨ï¼ä½æäºç¥åçååçè¨æç ´è¬ï¼å æ¤çºäºä¿éªèµ·è¦ï¼æ¯ç¬å ©åååå°±åæªä¸æ¬¡ï¼ä»¥é²è³æéºå¤±ã
dic = {
'ååå稱' : theproduct,
'çè¨ç¶²å' : theCommenturl,
'çè¨è
' : who,
'æç' : star,
'çè¨æé' : thetime,
'çè¨å°é»' : location,
'SKU' : sku,
'çè¨å
§å®¹' : comment,
'覺å¾çè¨æç¨äººæ¸' : helpful,
}
if data%2==0:
pd.DataFrame(dic).to_csv('å°ç¬¬'+str(data)+'ååå_Amazonçè¨è³æ.csv',
encoding = 'utf-8-sig',
index=False)</code></pre>
作者:楊超霆 行銷搬進大程式 創辦人